Data Modeling Examples and Frequently Asked Questions
Is every straight line the graph of a function?
Assume the random variable X has a binomial distribution with the given probability of obtaining a success. Find the following probability, given the number of trials and the probability of obtaining a success. Round your answer to four decimal places.
, n=6 p=0.4
Its binomial distribution I couldn't find an option for it
Assume the random variable X has a binomial distribution with the given probability of obtaining a success. Find the following probability, given the number of trials and the probability of obtaining a success. Round your answer to four decimal places.
, n=6 p=0.4
Its binomial distribution I couldn't find an option for it
the manager of an electrical supply store measured th diameters of the rolls of wire in the inventory. The diameter of the rolls are listed below 0.56, 0.622, 0.154, 0.412, 0.287, 0.118
the manager of an electrical supply store measured th diameters of the rolls of wire in the inventory. The diameter of the rolls are listed below 0.56, 0.622, 0.154, 0.412, 0.287, 0.118
A board game in a fieste carnival has the numbers 2 through 12. These numbers are the sum of the results in rolling todice. If you are going to place your bet on the numbers, what will you choose and why? Apply your knowledge on probabilitydistribution Show your solutions
Find the amount in a savings account after 12 years if $56,780 is invested at 2.8% interest compounded quarterly.
Under the normal curve, the probability of a score occurring below the mean is
0
68%
2 to 1
.50
Data Mining
Which of the following steps are done before data modeling? SELECT ONE
Data cleaning
Data reduction
Data transformation
All of the above
Data Mining
Which of the following steps are done before data modeling? SELECT ONE
Data cleaning
Data reduction
Data transformation
All of the above
The table below contains the information for the joint probability mass function of X and Y (two different measurement systems).
a) Plot and calculate the marginal distributions of X and Y
b) Select one of the Y values from the table and find the conditional probability mass function of X for that Y value you have selected and plot it.
c) Show whether X and Y are independent or not.
d) Calculate the covariance of (X,Y) i.e. Cov(X,Y).
The table below contains the information for the joint probability mass function of X and Y (two different measurement systems).
a) Plot and calculate the marginal distributions of X and Y
b) Select one of the Y values from the table and find the conditional probability mass function of X for that Y value you have selected and plot it.
c) Show whether X and Y are independent or not.
d) Calculate the covariance of (X,Y) i.e. Cov(X,Y).
Ron Larson - Calculus 11th Edition
Chp 3.3 Increasing and decreasing functions and the first derivative test.
Please show work and explain steps, thank you.
Modeling Data. The end-of-year assets of the Medicare
Hospital Insurance Trust Fund (in billions of dollars) for the
years 2006 through 2014 are shown.
2006: 305.4 2007: 326.0 2008: 321.3
2009: 304.2 2010: 271.9 2011: 244.2
2012: 220.4 2013: 205.4 2014: 197.3
(Source: U.S. Centers for Medicare and Medicaid Services)
(b) Use a graphing utility to plot the data and graph the model.
Chp 3.3 Increasing and decreasing functions and the first derivative test.
Please show work and explain steps, thank you.
Modeling Data. The end-of-year assets of the Medicare Hospital Insurance Trust Fund (in billions of dollars) for the years 2006 through 2014 are shown.
2006: 305.4 2007: 326.0 2008: 321.3
2009: 304.2 2010: 271.9 2011: 244.2
2012: 220.4 2013: 205.4 2014: 197.3
(Source: U.S. Centers for Medicare and Medicaid Services)
(b) Use a graphing utility to plot the data and graph the model.
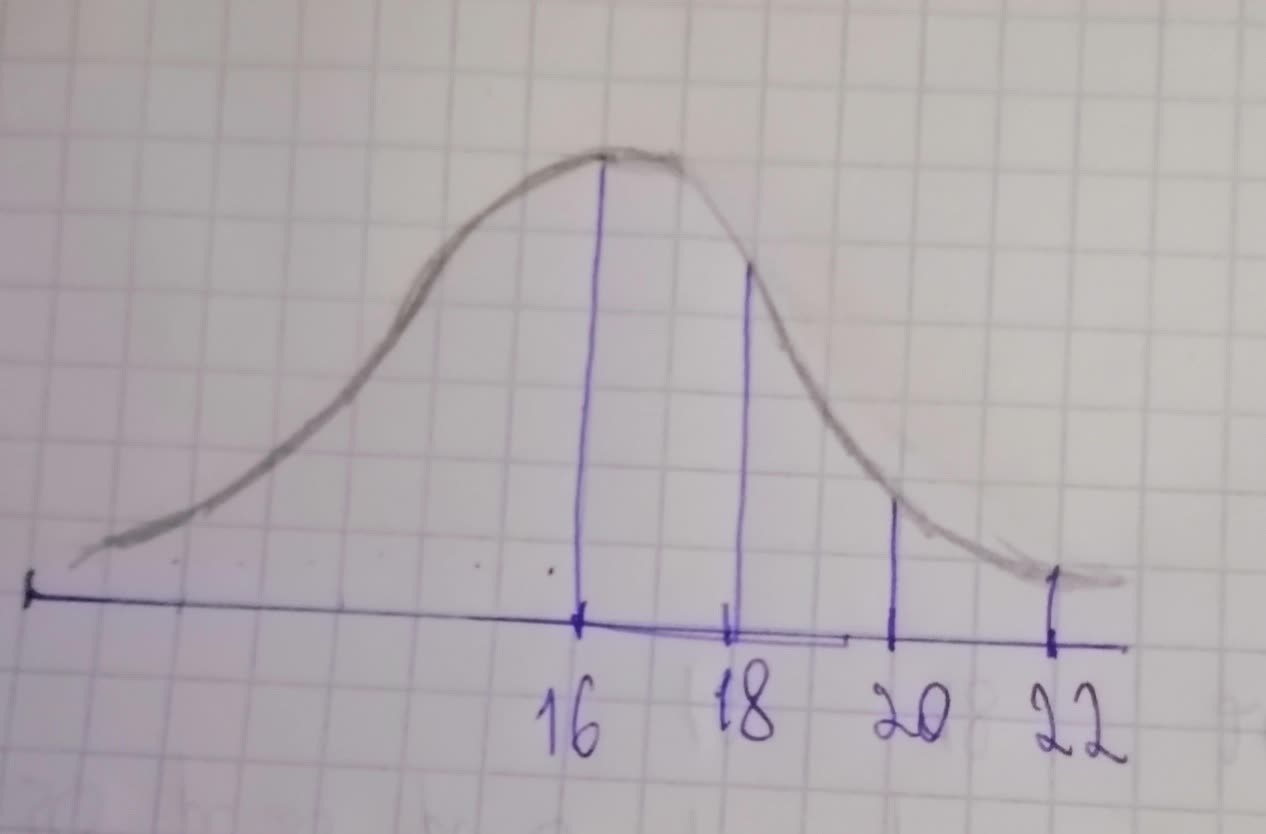
Look at the normal curve below, and find
The Great White Shark. In an article titled “Great White, Deep Trouble” (National Geographic, Vol. 197(4), pp. 2–29), Peter Benchley—the author of JAWS—discussed various aspects of the Great White Shark (Carcharodon carcharias). Data on the number of pups borne in a lifetime by each of 80 Great White Shark females are provided on the WeissStats site. Use the technology of your choice to
a. obtain frequency and relative-frequency distributions, using single-value grouping.
b. construct and interpret either a frequency histogram or a relativefrequency histogram.
a. obtain frequency and relative-frequency distributions, using single-value grouping.
b. construct and interpret either a frequency histogram or a relativefrequency histogram.
The data for the joint probability mass function of X and Y (two different measurement systems) are given in the table below.
a) Calculate the marginal distributions of X and Y and plot them.
b) Select one of the Y values from the table and find the conditional probability mass function of X for that Y value you have selected and plot it.
c) Show whether X and Y are independent or not.
d) Calculate the covariance of (X,Y) i.e. Cov(X,Y).
a) Calculate the marginal distributions of X and Y and plot them.
b) Select one of the Y values from the table and find the conditional probability mass function of X for that Y value you have selected and plot it.
c) Show whether X and Y are independent or not.
d) Calculate the covariance of (X,Y) i.e. Cov(X,Y).
Which of the following is nota condition for constructing a confidence interval to estimate the difference between two population proportions?
A. The samples must be selected randomly.
B. The data must come from populations with approximately normal distributions.
C. When samples are taken without replacement, each population must be at least 10 times as large as its corresponding sample.
D. The samples must be independent of each other.
E. The observed number of successes and failures for both samples must be at least 10.
A. The samples must be selected randomly.
B. The data must come from populations with approximately normal distributions.
C. When samples are taken without replacement, each population must be at least 10 times as large as its corresponding sample.
D. The samples must be independent of each other.
E. The observed number of successes and failures for both samples must be at least 10.
A random sample of
Previous studies show that
For Englewood (a suburb of Denver), a random sample of
Previous studies show that
Assume the pollution index is normally distributed in both Englewood and Denver.
(a) State the null and alternate hypotheses.
(b) What sampling distribution will you use? What assumptions are you making?
The Students
A random sample of
Previous studies show that
For Englewood (a suburb of Denver), a random sample of
Previous studies show that
Assume the pollution index is normally distributed in both Englewood and Denver.
(a) State the null and alternate hypotheses.
(b) What sampling distribution will you use? What assumptions are you making?
The Students
A standard 3 sigma x-bar chart has been enhanced with early warning limits at plus-minus one sigma from the centerline . Three sample means in a row have plotted above the +1 sigma line . what is the probability of this happening if the process is still in control.
The population mean may be reliably estimated using a statistic calculated from data recorded from randomly selected individuals.’ Explain this statement with reference to sampling distributions and the central limit theorem.
Range=max value- min value
h=r/m m=no of classes
The weights shown in data given to the nearest tenth of a pound, were obtained from a sample of 18- to 24-year-old males. Organize these data into frequency and relative-frequency distributions. Use a class width of 20 and a first cutpoint of 120.
129.2 185.3 218.1 182.5 142.8 155.2 170.0 151.3 187.5 145.6 167.3 161.0 178.7 165.0 172.5 191.1 150.7 187.0 173.7 178.2 161.7 170.1 165.8 214.6 136.7 278.8 175.6 188.7 132.1 158.5 146.4 209.1 175.4 182.0 173.6 149.9 158.6
Also calculate cumulative frequency and midpoint.
h=r/m m=no of classes
The weights shown in data given to the nearest tenth of a pound, were obtained from a sample of 18- to 24-year-old males. Organize these data into frequency and relative-frequency distributions. Use a class width of 20 and a first cutpoint of 120.
129.2 185.3 218.1 182.5 142.8 155.2 170.0 151.3 187.5 145.6 167.3 161.0 178.7 165.0 172.5 191.1 150.7 187.0 173.7 178.2 161.7 170.1 165.8 214.6 136.7 278.8 175.6 188.7 132.1 158.5 146.4 209.1 175.4 182.0 173.6 149.9 158.6
Also calculate cumulative frequency and midpoint.
Reporting summary measures such as the mean, median, and standard deviation has become very common in modern life. Many companies, government agencies will report these descriptive measures of a variable, but they will rarely provide information on the shape of the distribution of that variable. In previous tutorials, you have learned some basic properties of some distributions that can help you to decide if a specific type of distribution is a good fit for a set of data.
According to the National Diet and Nutrition Survey: Adults Aged 19 to 64, British men spend an average of 2.15 hours per day in moderate or high intensity physical activity. The standard deviation of these activity times for this sample was 3.59 hours. Can we infer that these activity times could follow a normal distribution? The following may provide an answer.
Suppose that the standard deviation for this sample was 0.70 hours instead of 3.59 hours, which make it numerically possible for the distribution to be normal. Again, considering the variable being measured, explain why the normal distribution is still not a logical choice for this distribution.
According to the National Diet and Nutrition Survey: Adults Aged 19 to 64, British men spend an average of 2.15 hours per day in moderate or high intensity physical activity. The standard deviation of these activity times for this sample was 3.59 hours. Can we infer that these activity times could follow a normal distribution? The following may provide an answer.
Suppose that the standard deviation for this sample was 0.70 hours instead of 3.59 hours, which make it numerically possible for the distribution to be normal. Again, considering the variable being measured, explain why the normal distribution is still not a logical choice for this distribution.