In the figure a worker lifts a weight \omega by pulling down on a rope with a force \vec{F}. The upper pulley is attached to the ceiling by a chain,an
ankarskogC
Answered question
2021-05-08
In the figure a worker lifts a weight by pulling down on a rope with a force . The upper pulley is attached to the ceiling by a chain,and the lower pulley is attached to the weight by another chain.The weight is lifted at constant speed. Assume that the rope,pulleys, and chains all have negligible weights. 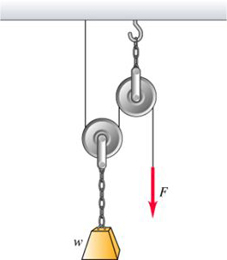
A) In terms of ,find the tension in the lower chain.
B) In terms of ,find the tension in upper chain.
C) In terms of ,find the magnitude of the force if the weight is lifted at constant speed.
Answer & Explanation
lamanocornudaW
Skilled2021-05-10Added 85 answers
So, according to the Newton’s 3rd law, there must be an equal force in the opposite direction. The opposite force balancing the downward force is called as tension in the lower chain.
It is mathematically given by,
Substitute w for F, where w is the weight which acts as force. T is tension.
Thus, the tension in the lower chain is w.
Part A:
According to the Newton’s 3rd law, force in the downward direction is always balanced equally by the force in the upward direction. Here, the force in the upward direction is in the form of tension. So, the tension in the lower chain is w.
The diagram given above shows the individual forces acting on the upper chain. Here, the force acting on the upper chain is the result of the half force applied by the person and half by the lower chain.
Thus, the force applied by the upper chain will be half of the original one. Thus,
Similarly, the force applied by the lower chain is given by,
Thus, the total force on the upper chain is given by,
So, force on the upper chain is w.
Part: B
The force on the upper chain is because of the lower chain as well as the force applied by the person. So, the contribution from both the factors is half-half.
In the upper pulley, you do not gain any mechanical advantages, however, the lower pulley reduces the required force by 1/2.
Thus, the magnitude of the force
Part C:
The magnitude of the force if the weight is lifted at constant speed will always be the half. It is seen from the diagram given above that the individual force acting on the spring is half, as other half of the force will be balanced by the opposing force from the chain.
New Questions in Electromagnetism
The magnetic field inside a long straight solenoid carrying current
A)is zero
B)increases along its radius
C)increases as we move towards its ends
D)is the same at all pointsWhich of the following units is used to express frequency?
Hertz
Watt
Newton
PascalWhat does tangential force produce?
How Many Different Orbitals Are There?
What is value for electrons ?
Which of the following correctly describes the magnetic field near a long straight wire?
A. The field consists of straight lines perpendicular to the wire
B. The field consists of straight lines parallel to the wire
C. The field consists of radial lines originating from the wire
D. The field consists of concentric circles centered on the wireIs energy directly proportional to frequency?
What is a compass? How is a compass used to find directions?
Magnetic field lines never intersect each other because
There will be two directions of the field at the same point.
Feild lines repel each other
Field lines follow discrete paths only
If field lines intersect they create a new magnetic field within the existing fieldTwo parallel wires carry currents of 20 A and 40 A in opposite directions. Another wire carrying a current antiparallel to 20 A is placed midway between the two wires. The magnetic force on it will be
Towards 20 A
Towards 40 A
Zero
Perpendicular to the plane of the currentWhat is the wavelength of the light emitted when an electron in a hydrogen atom undergoes transition from the energy level n = 4 to energy level n = 2? What is the colour corresponding to their wavelengths? (Given )
A) 486 nm, Blue
B) 576 nm, Blue
C) 650, Blue
D) 450 nm, BlueTwo identical conducting spheres A and B are separated by a distance greater than their diameters the spheres carry equal charges and electrostatic force between them is F a third identical uncharged sphere C is first brought in contact with A, then with B and finally removed as a result, the electrostatic force between A and B becomes
Why is alternating current used in homes?
Which of the following radiation has the shortest wavelength.
X-ray
Infra red
microwave
ultravioletHow to find the local extrema for ?