Pete is making 8 identical fruit baskets as gifts. Each basket contains some apples and 12 oranges. Pete uses a total of 168 pieces of fruit to make the baskets. Determine the number of apples that are in each basket.
Maiclubk
Answered question
2021-01-27
Answer & Explanation
AGRFTr
Skilled2021-01-28Added 95 answers
Let a represent the quantity of apples, resulting in a+12 fruits in each basket. Since there are 8 baskets for a total of 168 fruits, then we can write the equation: 8(a+12)=168
Divide both sides by 8: a+12=21
Subtract 12 from both sides: a=9
So, there are 9 apples in each basket.
New Questions in Algebra I
Find the volume V of the described solid S
A cap of a sphere with radius r and height h.
V=??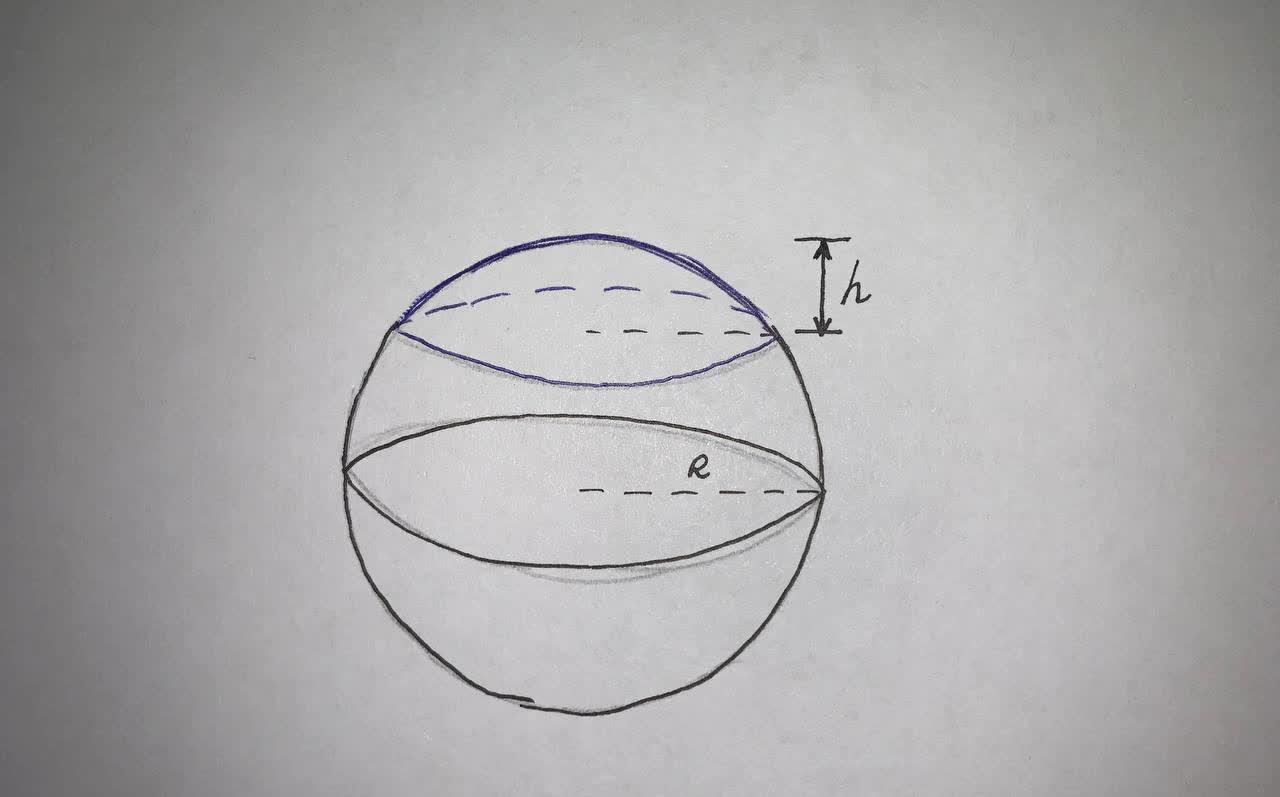
Whether each of these functions is a bijection from R to R.
a)
b)
c)
?In how many different orders can five runners finish a race if no ties are allowed???
State which of the following are linear functions?
a.
b.
c.
d.Three ounces of cinnamon costs $2.40. If there are 16 ounces in 1 pound, how much does cinnamon cost per pound?
A square is also a
A)Rhombus;
B)Parallelogram;
C)Kite;
D)none of theseWhat is the order of the numbers from least to greatest.
,
,
,
Write the numerical value of
Solve for y. 2y - 3 = 9
A)5;
B)4;
C)6;
D)3How to graph ?
How to graph using a table?
simplify
How to find the vertex of the parabola by completing the square ?
There are 60 minutes in an hour. How many minutes are there in a day (24 hours)?
Write 18 thousand in scientific notation.