Let <mo fence="false" stretchy="false">{ X 1 </msub> , …<!-- … -->
ttyme411gl
Answered question
2022-07-09
If not, how should I solve it? Alternating optimization?
(At first, I thought it may be related to the SVD of the sum of the matrices , but so far I have no hint to prove it.)
Answer & Explanation
Nicolas Calhoun
Beginner2022-07-10Added 15 answers
Let
Hence,
Let the Lagrangian be
where the Lagrange multipliers and are symmetric matrices. Taking the partial derivatives with respect to and ,
Finding where the partial derivatives vanish, we obtain two cubic matrix equations in and two quadratic matrix equations in and
How can one solve these matrix equations? I do not know.
Ximena Skinner
Beginner2022-07-11Added 7 answers
Note that are not orthogonal but they are ortho-projectors
Similarly, the vectors are not unit vectors but they satisfy simple normalization conditions
Write the objective function as
where colon denotes the inner/Frobenius product.
The main result of these manipulations was to recast the problem as a single matrix-vector equation. The vector gradients are then
This still isn't a solution to the problem, just another way of thinking about it.
New Questions in High school geometry
The distance between the centers of two circles C1 and C2 is equal to 10 cm. The circles have equal radii of 10 cm.
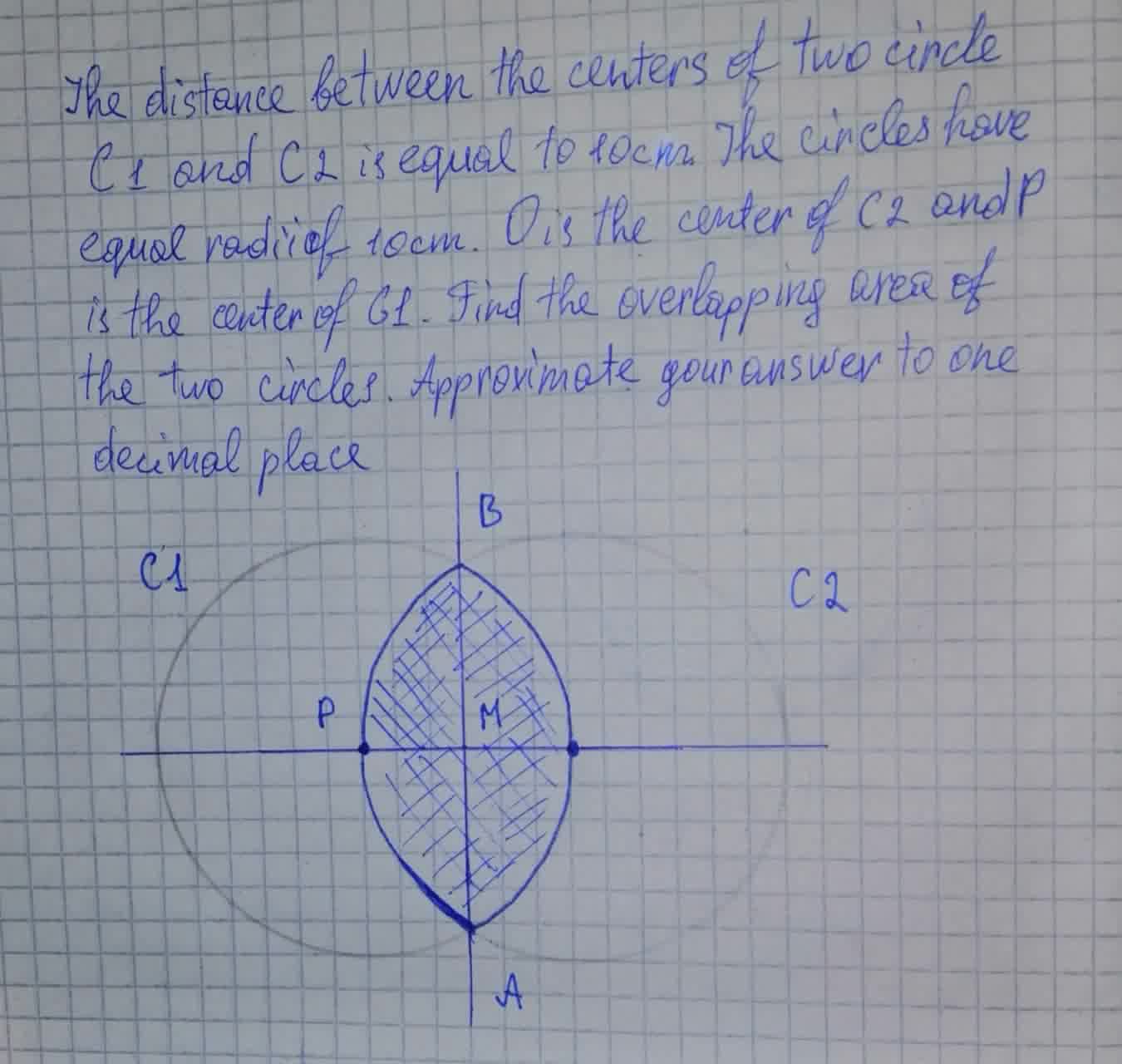
A part of circumference of a circle is called
A. Radius
B. Segment
C. Arc
D. SectorThe perimeter of a basketball court is 108 meters and the length is 6 meters longer than twice the width. What are the length and width?
What are the coordinates of the center and the length of the radius of the circle represented by the equation ?
Which of the following pairs of angles are supplementary?
128,62
113,47
154,36
108,72What is the surface area to volume ratio of a sphere?
An angle which measures 89 degrees is a/an _____.
right angle
acute angle
obtuse angle
straight angleHerman drew a 4 sided figure which had only one pair of parallel sides. What could this figure be?
Trapezium
Parallelogram
Square
RectangleWhich quadrilateral has: All sides equal, and opposite angles equal?
Trapezium
Rhombus
Kite
RectangleKaren says every equilateral triangle is acute. Is this true?
Find the number of lines of symmetry of a circle.
A. 0
B. 4
C. 2
D. InfiniteThe endpoints of a diameter of a circle are located at (5,9) and (11, 17). What is the equation of the circle?
What is the number of lines of symmetry in a scalene triangle?
A. 0
B. 1
C. 2
D. 3How many diagonals does a rectangle has?
A quadrilateral whose diagonals are unequal, perpendicular and bisect each other is called a.
A. rhombus
B. trapezium
C. parallelogram