For the following questions you must use the rules of logic (Don’t use truth tables) a) Show that (p harr q) and (not p harr not q ) are logically equivalent. b) Show that not ( p o+ q) and (p harr q) are logically equivalent.
permaneceerc
Answered question
2021-02-19
a) Show that (
b) Show that not (
Answer & Explanation
Brittany Patton
Skilled2021-02-20Added 100 answers
Double negation law:
Commutative laws:
De Morgan's laws:
a)
b)

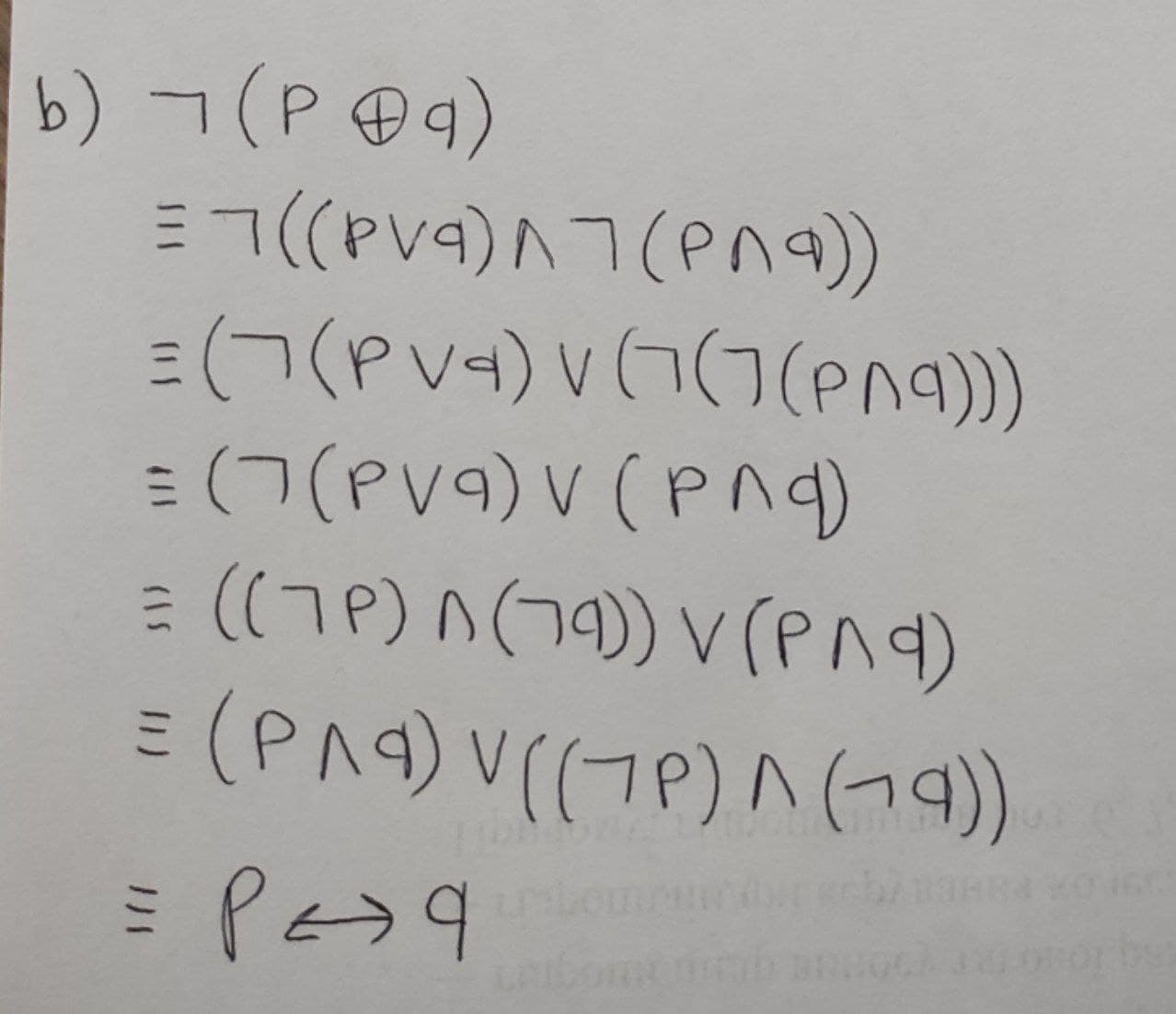
New Questions in Discrete math
Show that the sequence is an solution of the recurrence relation [a^n = a^n−1 + 2a^n−2 + 2n − 9 if a] if
a^n = −n + 2
Why does a magnet always attract iron, not wood?
Why is not an onto function?
I was doing an example in a book where it asked which of these functions are one to one, the answer in the back said for that it is a one to one function. Then it asked which of the functions from the previous example are onto and was not included in the list of onto functions.
In a later example, a question asked which of these functions is a bijection, the answer included
This is confusing because doesn't a function have to be both an onto and one to one to be a bijection? Why would the book say it was not a onto in a previous example yet declare it to be a bijection? Is the book wrong?What is the meaning of l.h.s and r.h.s?
Showing that if n is a natural number larger than 3, then
Showing that if n is a natural number larger than , then
My try:
Base Case:
If , then
So, the base case is true.
Assuming is true.
Now we need to show that is true.
Proof:
After this I have no idea how to solve further.
Can anyone explain how to continue.What type of material allows electrons to flow freely?
Conductor
Resistor
Hestitation
RegulatorA set X with cardinality X has how many elements in its power set (the set of all subsets of a set)?
a.
b.
c.
d.Why is the value of is ?
Can a dot product of a permutation of n (1,-1) with a sequence of primes generate unique numbers?
According to Fundamental Theorem of Arithmetic any positive whole number is the product of primes. Therefore, I can create unique numbers by multiplying n primes.
If I have a list of length n generated by a finite sequence in the set 1,-1, e.g., (1,1,-1,-1,1,...), and I do a dot product with a sequence of n primes starting with 3, e.g., (3,5,7,11,13,...), do I have any guarantee that I will generate unique numbers by doing different permutations of 1s and -1s?
I know that I can't if my prime's sequence start with 2, , but I'm not sure for the cases where my sequence starts with higher primes.Maximize sum of paired products without replacement from {1,…,2n}
Given {1,…,2n}, how do you pair off the elements such that: when you multiply within each of the n pairs, the resulting products have maximal sum?
Here is an example: For , this would mean pairing off elements of {1,2,3,4}, taking the product within each pair, and then adding all of those products up: where the goal is to maximize the resulting sum.
In this example, you could use:
Since the pairwise product sums in this case are 14,11, and 10, we find that the maximum is 14. In particular, the maximum occurs when we pair off consecutive numbers. I suspect that the consecutive pairing may always be optimal (and that pairing first with last, second with second to last, etc may always result in the minimal pairwise product sum).
I'm not sure how to prove (or disprove!) this, and would appreciate a proof or a pointer to one. I suspect this problem has already been considered, so I include a ref-req tag as there may be terminology unfamiliar to me. If there are generalizations of this problem (e.g., starting with a set other than the first consecutive 2n positive integers) then related references will be most welcome, too!Compute summation of modules expression?
In particular, what I want to look at is the sum
where can be assumed to be coprime but it would be best if solved in the fullest generality. In the above expression, n is a variable, p,q are fixed, and a(modb) means taking the representative set . For example, is the only value we agree upon and .
The problem with this is that the list of representatives are permuted by p and hence the methods presented in the initial link are no longer valid.
It would be nice if we can come up with a closed form, but a really tight upper bound of the expression also works.Counting words of length n from k-sized alphabet with no substring of k consecutive distinct letters
How many words of length n are there, if we have an alphabet of k distinct letters, but the words cannot contain any substring that is made of k consecutive distinct letters, i.e, no k-length substring that consists of the entire alphabet?
Other than that, no restrictions apply: any amount of distinct letters may be used throughout the entire word, and any letter can be used as many times as we like, as long as every substring inside the length n word complies with the rules above.
There is the obvious case of which results in 2 words, for every n, because you can only start with either letter, and they alternate.
For the larger case, I have come up with a recursive formula:
With d being the current length of consecutive distinct letters, and i the current word length.
At every step, we can either use a letter other than the previous d letters, in which case the length is increased by one, and the chain-length d of distinct consecutive letters is also increased by one. In this case, there are such letters we can use at the stage, each subsequently resulting in the same contribution.
Or, we can use a letter already in the last d letters. In this case, the position of the letter matters. If we use the last of the d letters, a whole new chain begins. If instead we use the second last d letter, then a chain of length 2 of consecutive distinct letters begins. The 3rd last would result in a chain of length 3 and so on.
I was wondering if there is a another way to count the amount of such words, perhaps using matrices or combinatorics?Maximum number of edges in a graph satisfying conditions
There is a graph with 40 vertices. It is known that any edge has at least one endpoint, on which no more than four other edges are incident. What is the maximum number of edges that this graph can have? No multiple edges or loops are allowed.For each value for a and b, being real numbers,
Should I solve this by replacing all possible real number formulas in these to be able to prove this? As an example for odd numbers, by replacing , etc...?Representative Set for Relation S on s.t. bijection s.t.
Problem: Define a relation S on as follows: there exists a bijection s.t. .
S is an equivalence relation on (no need to prove this). Write a Representative set for the relation S. There's no need to prove that the relation you wrote is indeed a Representative set.
Reminder: Suppose is an equivalence relation over X. will be called a Representative set of T, if it occurs that: .
Attempt: I don't really know what Representative set to define. It seems to me I'm missing something simple here. I tried to look at the functions: , . None of these functions relate through relation S since there does not exist a bijection between them. I feel lost, do you have any idea what to do?