Polynomial function graphs have similarities depending on their degree. Explain how you can determine the best regression model by using finite differences. Then determine the end behavior of the graph based on the degree of a function and information gathered from a data table.
rocedwrp
Answered question
2020-11-08
Answer & Explanation
Brittany Patton
Skilled2020-11-09Added 100 answers
Step 1
Determining the best regression model by using finite differences. The method of finite differences is used for curve fitting with polynomial models. It is best introduced by an example as shown in table given below. For the sequence of x value inputs at the regularly spaced points
Table 1 is given below.
From the table, we can understand that this is third difference finite function of third degree.
This explains
Step 2
Here we need to find the value of a, b, c and d
Step 3
Taking
Also
Moreover,
Thus, finding b and c by subtracting and adding equation (1) and (2)
At last the finite function becomes:
Step 4
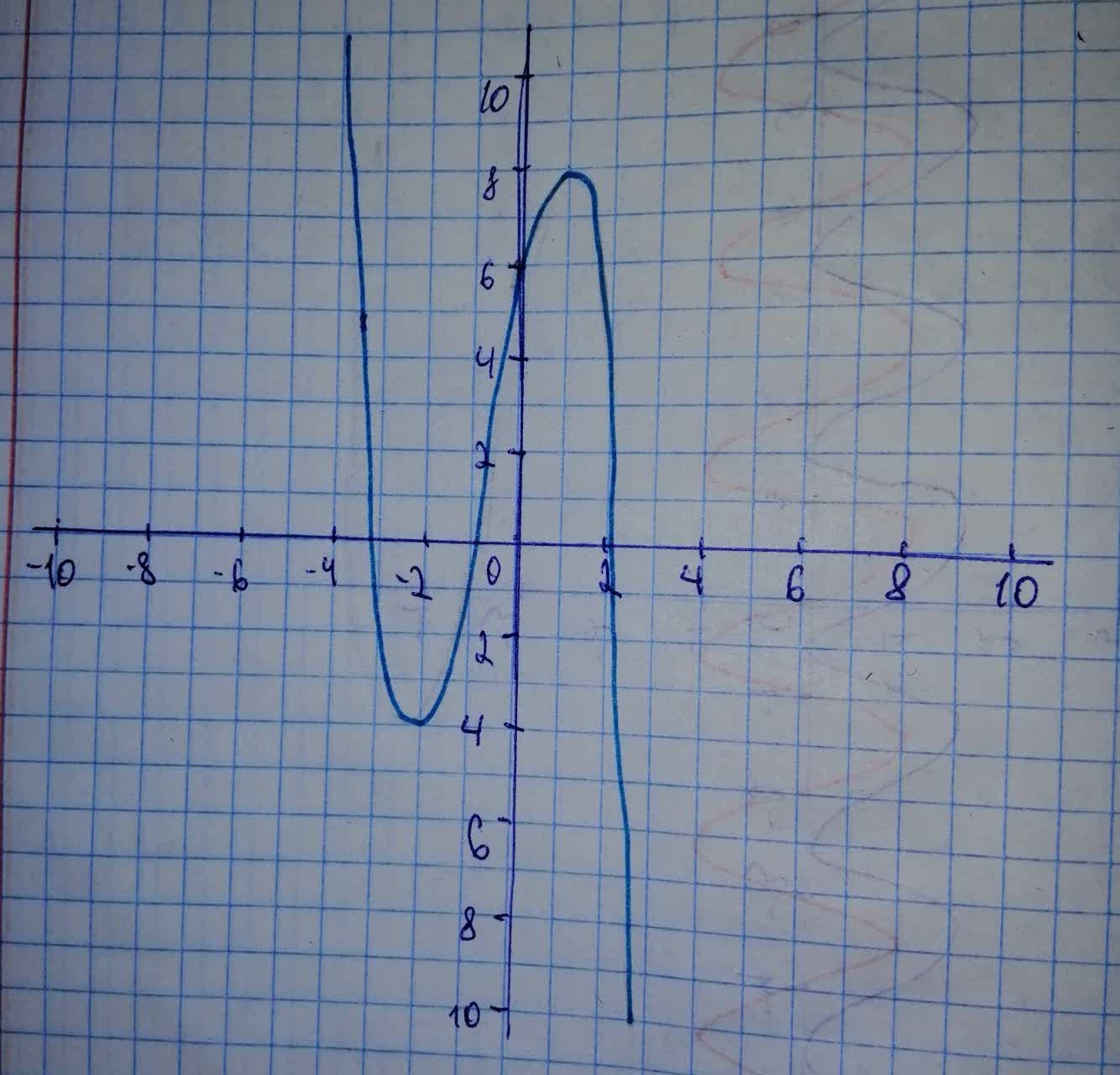
Sketching a grph from the function found above
Thus, end behaviour of
is described from the table as below
As
New Questions in Algebra I
Find the volume V of the described solid S
A cap of a sphere with radius r and height h.
V=??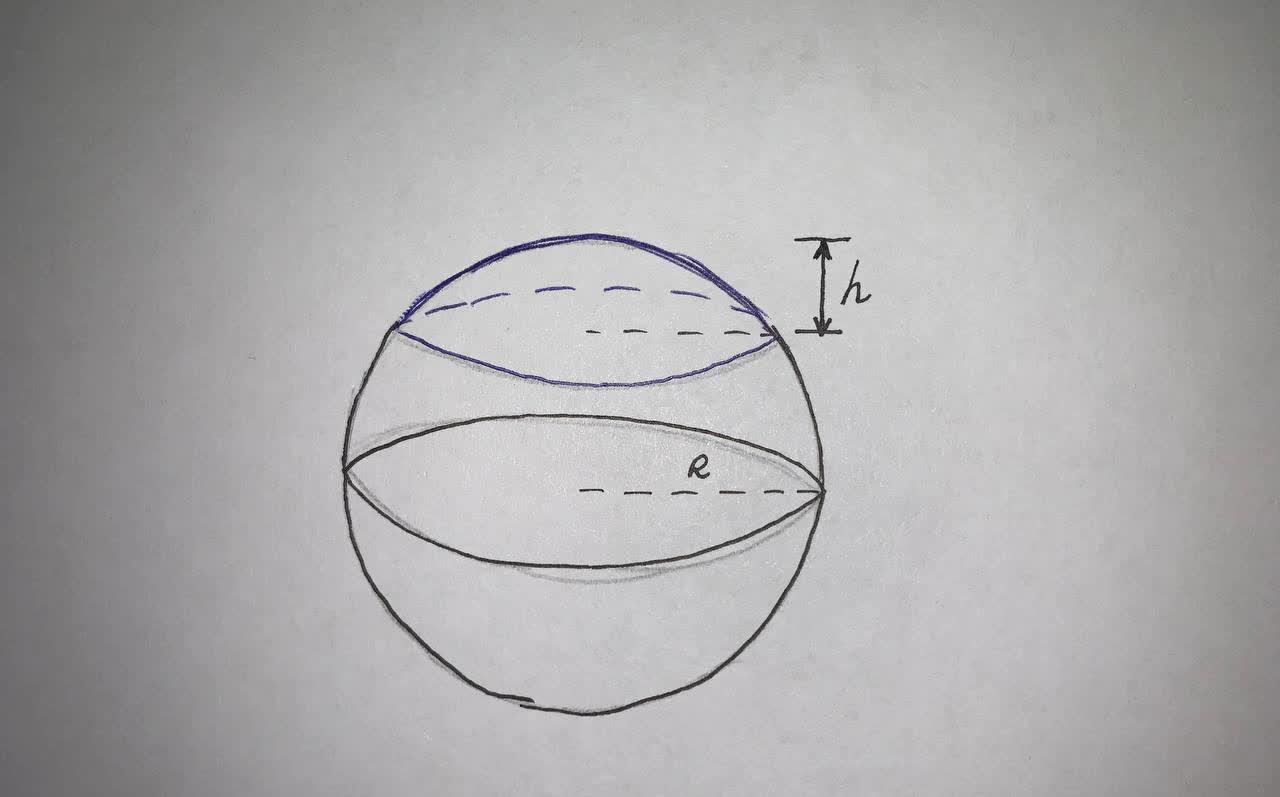
Whether each of these functions is a bijection from R to R.
a)
b)
c)
?In how many different orders can five runners finish a race if no ties are allowed???
State which of the following are linear functions?
a.
b.
c.
d.Three ounces of cinnamon costs $2.40. If there are 16 ounces in 1 pound, how much does cinnamon cost per pound?
A square is also a
A)Rhombus;
B)Parallelogram;
C)Kite;
D)none of theseWhat is the order of the numbers from least to greatest.
,
,
,
Write the numerical value of
Solve for y. 2y - 3 = 9
A)5;
B)4;
C)6;
D)3How to graph ?
How to graph using a table?
simplify
How to find the vertex of the parabola by completing the square ?
There are 60 minutes in an hour. How many minutes are there in a day (24 hours)?
Write 18 thousand in scientific notation.