For the following exercises, use a graphing utility to create a scatter diagram of the data given in the table. Observe the shape of the scatter diagram to
ddaeeric
Answered question
2021-02-18
For the following exercises, use a graphing utility to create a scatter diagram of the data given in the table. Observe the shape of the scatter diagram to determine whether the data is best described by an exponential, logarithmic, or logistic model. Then use the appropriate regression feature to find an equation that models the data. When necessary, round values to five decimal places.
Answer & Explanation
au4gsf
Skilled2021-02-19Added 95 answers
Step 1
Remember that regression analysis is the process of looking for a best fit of model for a set of data. This can be done on a graphing utility as follows:
1. Press [STAT], the input corresponging x-values of data in L1, and y-values of data in L2.
2. Use [STATPLOT] to observe a scatterplot of the data.
3. Press [STAT], then [CALC] then [ExpReg]/[LnReg]/[Logistic].
This will show you a function in either the form of an exponential, a logarithmic or a logistic model.
4. Graph this equation on the same window as the scatterplot to see if it fits the data.
Step 2
1. Press [STAT], the input corresponging x-values of data in L1, and y-values of data in L2.
2. Use [STATPLOT] to observe a scatterplot of the data.
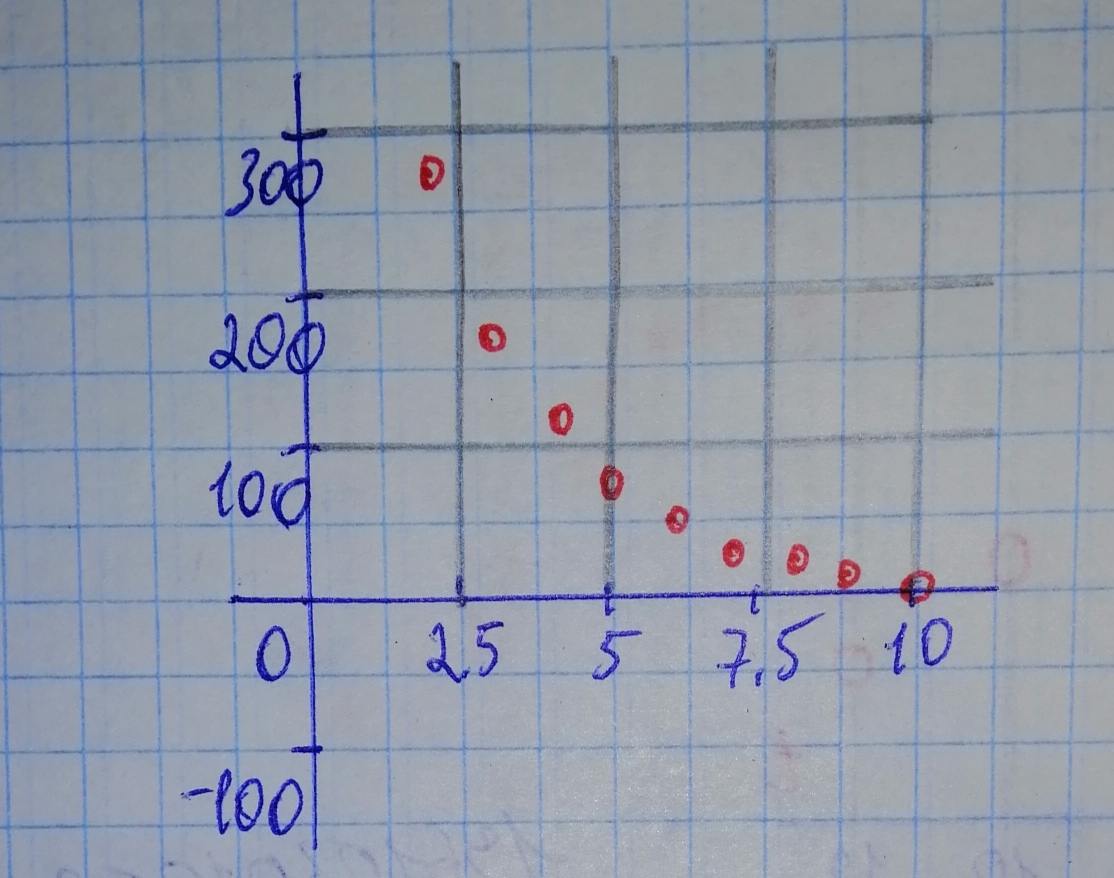
Step 3
Based on the plots of the points, it can be exponential or logarithmic.
However, upon checking both regression analysis, the one with the closest value of
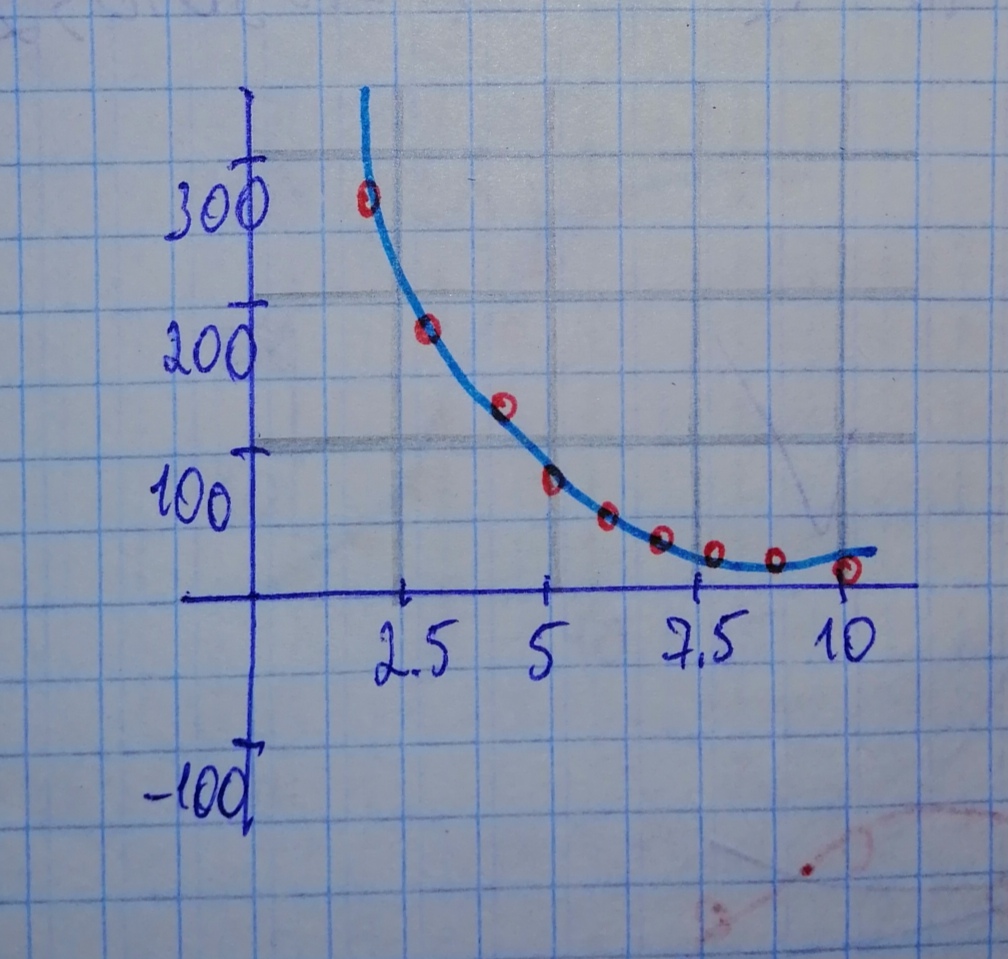
New Questions in Algebra II
Which operation could we perform in order to find the number of milliseconds in a year??
Tell about the meaning of Sxx and Sxy in simple linear regression,, especially the meaning of those formulas
Is the number 7356 divisible by 12? Also find the remainder.
A) No
B) 0
C) Yes
D) 6What is a positive integer?
Determine the value of k if the remainder is 3 given
Is a prime number?
What is the square root of ?
Is the sum of two prime numbers is always even?
149600000000 is equal to
A)
B)
C)
D)Find the value of to the base ?
What is the square root of 3 divided by 2 .
write as an equivalent expression using a fractional exponent.
simplify
What is the square root of