There is currently a global pandemic and many researchers and scientists are working assiduously to find a vaccine. Assume that Advanced Researcher, a
ringearV
Answered question
2021-03-07
Which probability distribution would you use to calculate the probability of success or failure of Advanced Researcher's vaccine if it were to be administered to people in society?
Answer & Explanation
firmablogF
Skilled2021-03-08Added 92 answers
Given,
There is currently a global pandemic and many researchers and scientists are working assiduously to find a vaccine. Assuming that Advanced Researcher, a company that is currently testing a few vaccines confirms an 80% chance of effectiveness of one of their vaccines.
Step 2
The probability distribution that we would use to calculate the probability of success or failure of Advanced Researchers
New Questions in Upper Level Math
If two angles of two triangles are congruent to each other, then the third angles will be congruent to each other. Using the above statement, choose which two congruency criteria eventually becomes same.
A)SAS and ASA;
B)AAS and SAS;
C)AAS and ASA;
D) No two congruency criteria are sameEvaluate
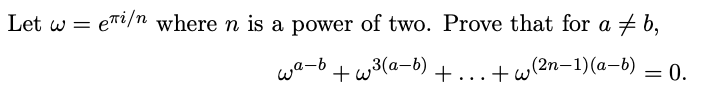
Solve the following differential equation dx/dy=-[(4y2+6xy)/(3y2+2x)]
The velocity distribution for laminar flow between parallel plates is given by:
where h is the distance separating the plates and the origin is placed midway between the plates. Consider a flow of water at , with and . Calculate the shear stress on the upper plate and give its direction.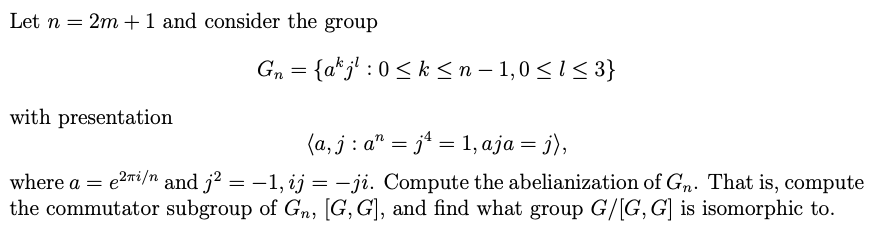
In August 2013, E*TRADE Financial was offering only 0.05% interest on its online checking accounts, with interest reinvested monthly. Find the associated exponential model for the value of a $5000 deposit after "t" years. Assuming that this rate of return continued for 7 years, how much would a deposit of $5000 in August 2013 be worth in August 2020? (Answer to the nearest $1. )
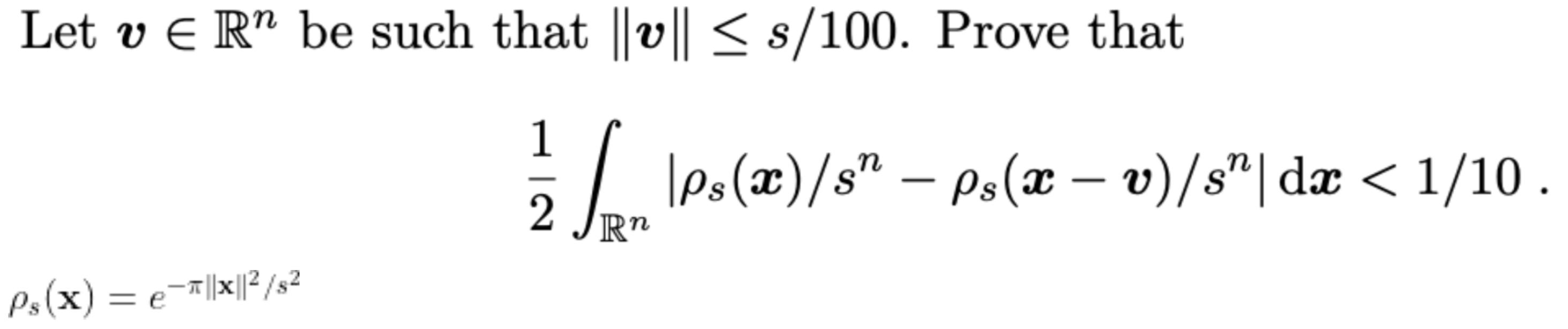
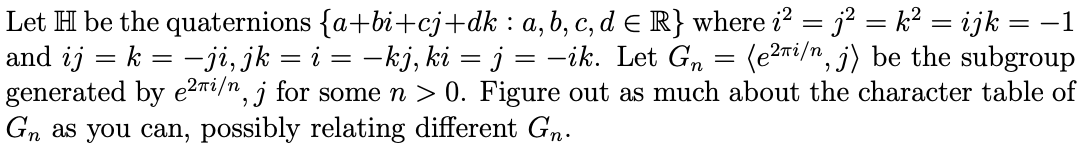
Write an equivalent first-order differential equation and initial condition for y
y=−1+∫x1(t−y(t))dt
Is {8} ∈ {{8}, {8}}?
