Why do you think we should learn about quadratic equations? how are they different from linear equations, and what is the significance of quadratic equation in the business world. Make sure you provide very specific examples to help us understand your explanation.
Ava-May Nelson
Answered question
2021-03-12
Answer & Explanation
funblogC
Skilled2021-03-13Added 91 answers
Quadratic equations are equations of degree 2. Linear equations have only one degree but quadratic have 2 degrees.
The general form of the quadratic and linear equation is given as quadratic equation:
linear equation:y=ax+b
where a,b,c are the constants
Quadratic equations are compulsory to be learnt as they extend the knowledge and applications more than linear equations.
Since, a lot of the physics equation can be modeled through quadratic equations like throwing a ball.
In the business world, sometimes the business people are interested only in deviations in absolute value. In other words, they are not bothered whether more or less and how much it varies on either side. In those cases, quadratic being square provides them with good idea.
All quadratic equations have either minimum or maximum thus helps business people to find optimum level. Also by learning quadratic only we come across imaginary and complex roots. Thus our knowledge is broadened by learning discriminant of quadratic equations and how it controls the nature of roots. Also learning quadratic helps us to solve for equations of higher degrees using factorization, synthetic division, etc.
New Questions in Algebra I
Find the volume V of the described solid S
A cap of a sphere with radius r and height h.
V=??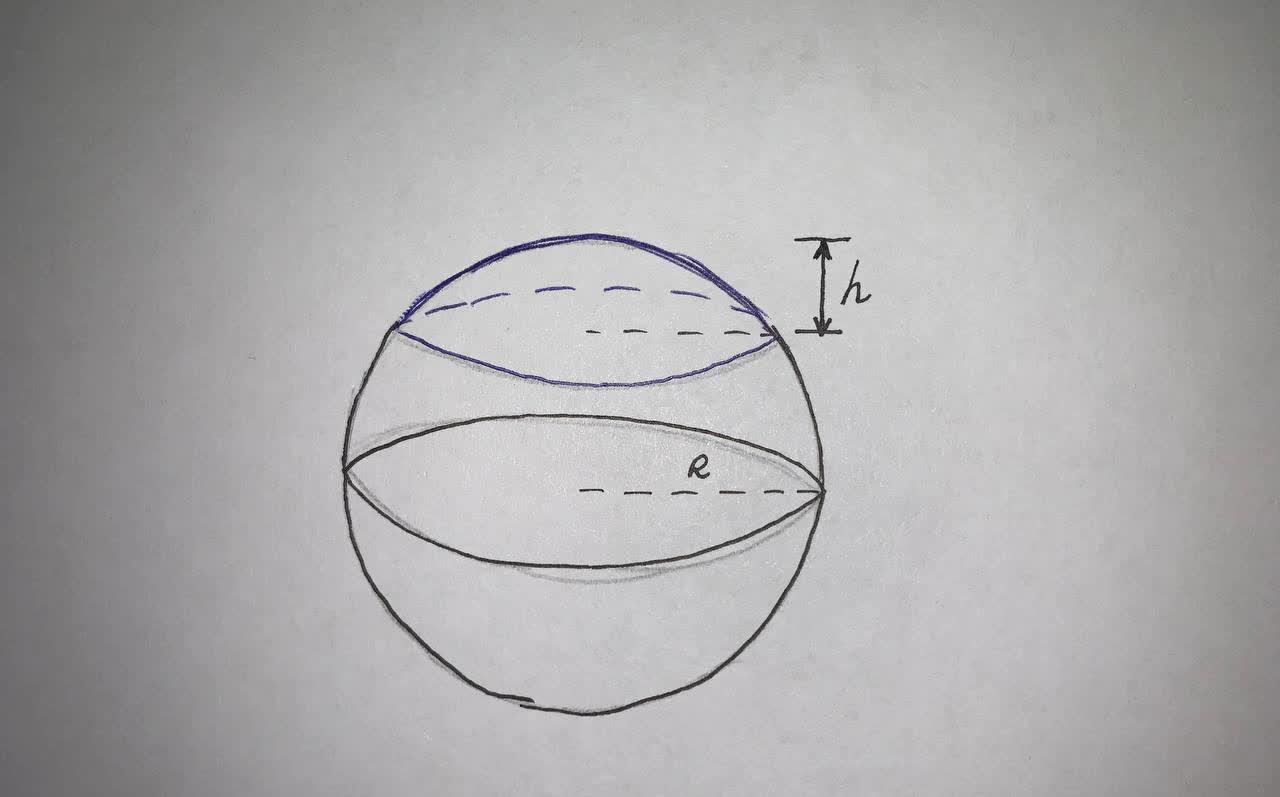
Whether each of these functions is a bijection from R to R.
a)
b)
c)
?In how many different orders can five runners finish a race if no ties are allowed???
State which of the following are linear functions?
a.
b.
c.
d.Three ounces of cinnamon costs $2.40. If there are 16 ounces in 1 pound, how much does cinnamon cost per pound?
A square is also a
A)Rhombus;
B)Parallelogram;
C)Kite;
D)none of theseWhat is the order of the numbers from least to greatest.
,
,
,
Write the numerical value of
Solve for y. 2y - 3 = 9
A)5;
B)4;
C)6;
D)3How to graph ?
How to graph using a table?
simplify
How to find the vertex of the parabola by completing the square ?
There are 60 minutes in an hour. How many minutes are there in a day (24 hours)?
Write 18 thousand in scientific notation.