[Table]A real-estate agent is trying to determine the relationship between the distance a 3-bedroom home is from New York City and its average selling price. He records the data for 6 homes shown below.Linear or Quadratic?Equation:Approximate cost of home 90 miles from NYC?
Efan Halliday
Answered question
2021-02-09
Answer & Explanation
berggansS
Skilled2021-02-10Added 91 answers
Input the x-values under L1 in a graphing calculator and the y-values, in thousands, under L2 (for example, input 755,000 as 755). Then graph the scatterplot to determine whether it is quadratic or linear: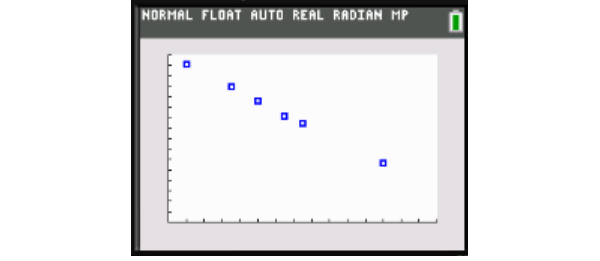
The data is linear because the points roughly lie on a straight line.
Use the LinReg feature on your graphing calculator to find the values of a and b for the line of best fit: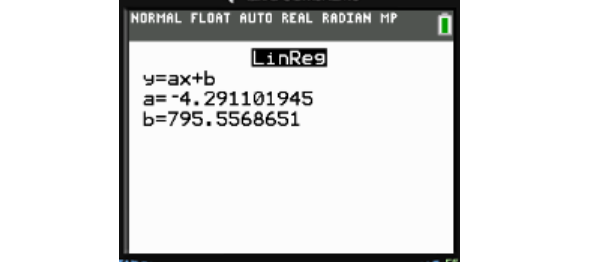
Since and , the equation is
If a home is miles from NYC, then (round to the nearest whole number since the costs in the table are rounded to the nearest thousand). The cost of the home is then about $409,000
New Questions in Algebra I
Find the volume V of the described solid S
A cap of a sphere with radius r and height h.
V=??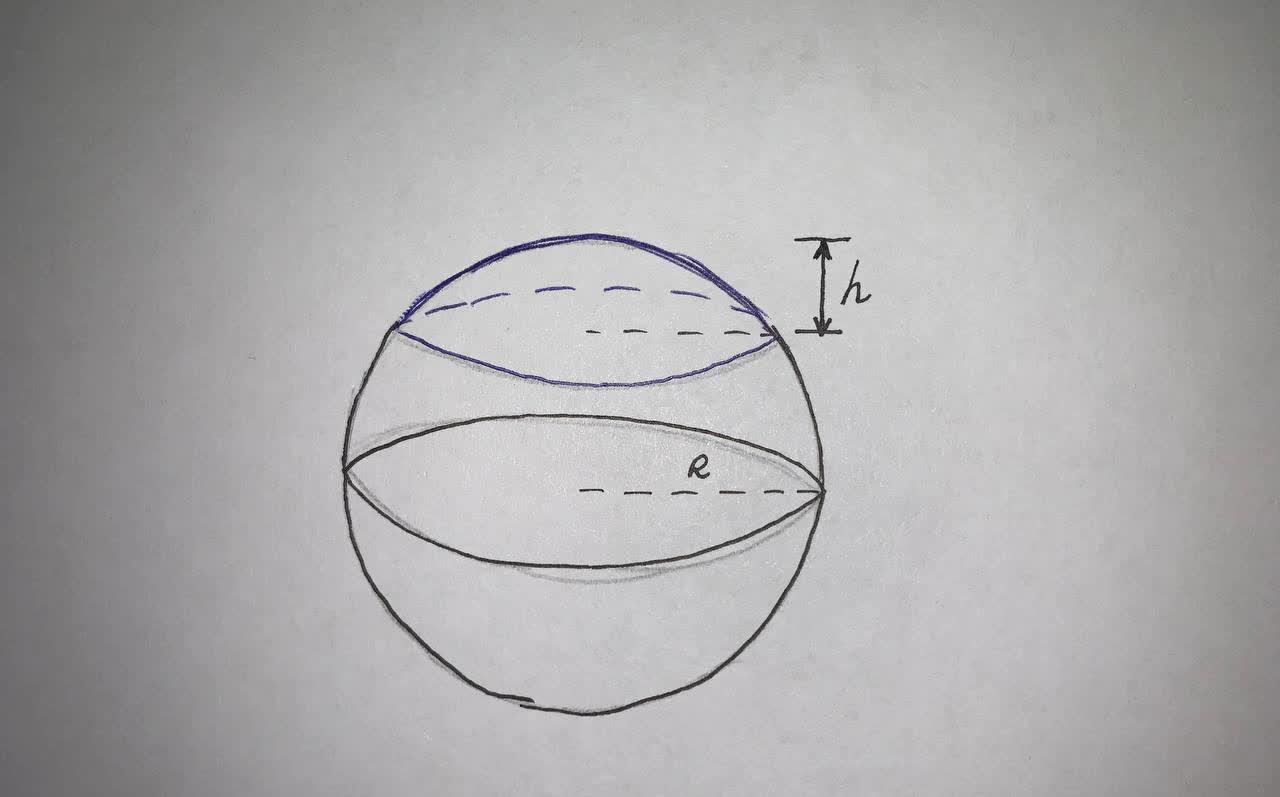
Whether each of these functions is a bijection from R to R.
a)
b)
c)
?In how many different orders can five runners finish a race if no ties are allowed???
State which of the following are linear functions?
a.
b.
c.
d.Three ounces of cinnamon costs $2.40. If there are 16 ounces in 1 pound, how much does cinnamon cost per pound?
A square is also a
A)Rhombus;
B)Parallelogram;
C)Kite;
D)none of theseWhat is the order of the numbers from least to greatest.
,
,
,
Write the numerical value of
Solve for y. 2y - 3 = 9
A)5;
B)4;
C)6;
D)3How to graph ?
How to graph using a table?
simplify
How to find the vertex of the parabola by completing the square ?
There are 60 minutes in an hour. How many minutes are there in a day (24 hours)?
Write 18 thousand in scientific notation.